On Thursday, Oct. 23, the Whiting School of Engineering’s Department of Computer Science hosted Aaron Roth, a professor of computer and cognitive science in the Department of Computer and Information Science at the University of Pennsylvania, to give a talk titled "Agreement and Alignment for Human-AI Collaboration." This talk involves the results of three papers: Tractable Agreement Protocols (2025 ACM Symposium on Theory of Computing), Collaborative Prediction: Tractable Information Aggregation via Agreement (ACM-SIAM Symposium on Discrete Algorithms) and Emergent Alignment from Competition.
With the rise of artificial intelligence in all sectors and fields, researchers attempt to answer the question of how it can help humans make important decisions. Roth uses the example of using AI to assist doctors in diagnosing patients. The process would involve the AI making predictions based on factors such as past diagnosis, blood types or other symptoms. The decision would then be evaluated by the human doctor, who can agree or disagree with the AI’s predictions based on their own knowledge, such as patient appearance.
However, Roth goes on to explain how if a disagreement occurs, the doctor and AI model can then reiterate their opinions for a finite number of rounds, integrating each other's unique view point each time, until eventually, the two will come to an agreement. This agreement occurs because both parties know that the other has knowledge they don’t have access to, and can therefore reach equilibrium. This is called a common prior, meaning both parties begin with the same underlying assumptions about the world, even if they hold different pieces of evidence. With these conditions, the two parties are considered perfect Bayesians.
Roth calls this agreement Perfect Bayesian Rationality, where both parties have their own set of knowledge. While party A knows what kind of knowledge party B has, it doesn’t know the specific details and vice versa. However, this idea has a few drawbacks, for instance, having a common prior in the first place can be difficult. Additionally, as the world itself is complicated, it can be difficult to fully reach agreement. When adding in multi-dimensional topics, such as hospital diagnostic codes, this task can become impossible for humans and AI.
Roth then goes on to explain how calibration can be used for these agreements. In order to understand calibration, Roth explains it as a test, for instance, to see if a weather reporter is forecasting correctly.
“You can sort of design tests such that they would pass those tests if they were forecasting true probabilities. It is also possible to fail those tests, and calibration is one of those tests.”
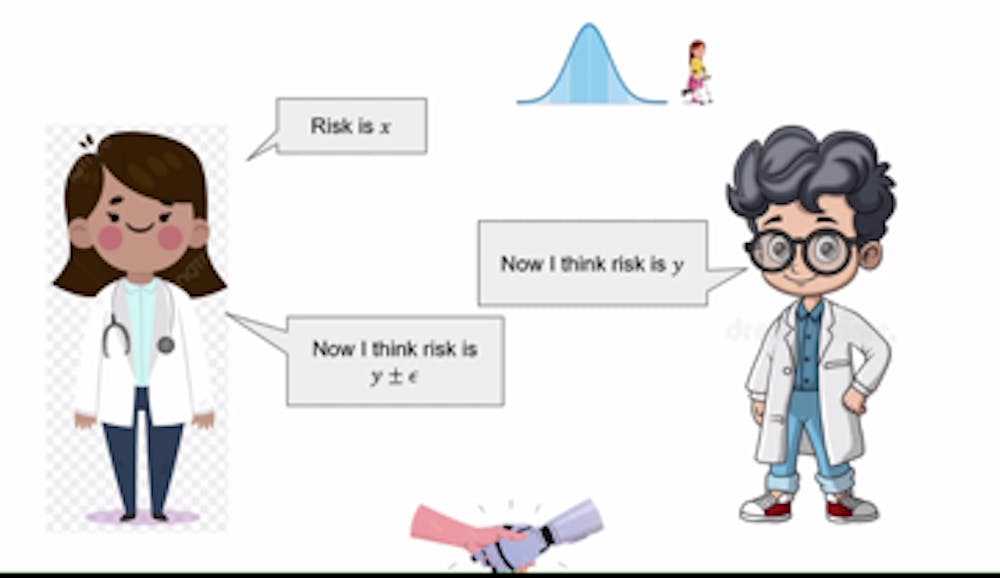
Roth then introduces conversation calibration, a condition assumed between the doctor and AI. This conditionality means that claims by one of the parties can be based upon what their counterparty made in the prior round. For instance, if the AI claims there is a 40% risk in treatment, and the doctor claims the risk is 35%, then the AI will base its next claim on the doctor’s prediction, leading to a risk percentage lower than 40 but higher than 35. This continues until an agreement is made. This calibration allows for faster agreements between the parties.
So far, this scenario has been assuming both parties have the same end goal, however, this does not have to be the case. If an AI model is developed by a higher company, there may be concerns of other subconscious goals that the doctor isn’t aiming for. Roth changes the scenario, where now the AI is developed by a drug company, and while it still aims to prescribe patient treatments, it may have an affinity for prescribing the company’s medications. Roth suggests that in this scenario, doctors should consult multiple LLMs. If multiple drug companies each have their own misaligned models, the doctors can consult each one and then choose the best course of action overall. This would cause competition in the market as each LLM provider attempts to make their model the one the doctor will agree with, overall causing all models to become more aligned and less biased, simply due to market competition.
Roth concludes by discussing the concept of real probabilities — the true, underlying probabilities that describe how the world actually works. While these probabilities are the most accurate and unbiased in real world conditions, it is rare that that specific precision is necessary. Instead, it is often sufficient for probabilities to remain unbiased under a limited set of conditions. In these cases, we can estimate accurate and reliable probabilities directly from data, without requiring the full complexity of perfect reasoning. Through these conditions, doctors and AI could collaborate to form agreements about accurate treatments, diagnoses and more.